Come funziona
Il mondo dei barcode si è allargato notevolmente negli ultimi anni, sotto la spinta di meccanizzare quanto più possibile la gestione delle merci e delle informazioni ad esse correlate.
L’evoluzione dei dispositivi elettronici, sia per rilevare e analizzare il codice in sè, sia per analizzare i dati in esso contenuti, ha portato alla nascita a codici sempre più sofisticati, tanto che oggi, per aumentare la densità di informazione, ne esistono di bidimensionali e facenti uso di più colori.
In questo paragrafo trattiamo solo i principi base su cui si basa il funzionamento del tipo più comune di barcode, oggi largamente usato nei beni da supermercato: i codici UPC/EAN
Nella creazione di un codice a barre è necessario associare al simbolo che si vuole rappresentare, lettera, numero o simbolo grafico, una sequenza di linee di differente spessore. Ciascuna linea può essere una barra nera o uno spazio bianco (o del colore dello sfondo su cui è stampato il codice).
Si può fare una prima suddivisione fra due tipi di codice: discreti e continui. I primi hanno una codifica in cui ciascun simbolo è indipendente dagli altri e inizia e finisce con una barra. Gli spazi fra un simbolo e l’altro sono ignorati.
Nei codici continui, i simboli non sono indipendenti in quanto l’inizio di un carattere determina la fine del precedente. E’ necessario quindi che ogni simbolo finisca con uno spazio e inizi con una barra o viceversa. La codifica UPC/EAN appartiene a questa categoria.
Come anticipato nel precedente paragrafo, lo standard UPC (Universal Product Code) è stato varato nel 1973 negli Stati Uniti ad opera del consorzio GS1 e da allora è diventato lo standard per la distrubuzione delle merci al dettaglio nel nordamerica e in molti altri paesi.
In seguito gli si è affiancato l’ EAN (European Article Numbering) pensato per adattarne le caratteristiche ad una realtà più diversificata come quella europea, come vedremo più sotto.
Vediamo dapprima come si compone un simbolo UPC e in particolare il cosiddetto UPC-A, che rappresenta la versione più estesa. A fianco all’UPC-A esiste l’UPC-E che deriva dall’UPC-A ma ha dimensioni ridotte per essere usato su confezioni che sarebbero troppo piccole per ospitare un UPC-A completo.

Osservando l’esempio di barcode sopra riportato possiamo notare alcuni elementi caratteristici:
- In basso è riportato il valore in formato “umanamente leggibile” del valore codificato nel simbolo. Un codice UPC può codificare solo le dieci cifre 0-9 ed è composto da 12 caratteri
- A sinistra e a destra del simbolo sono presenti due “quiet zones” rappresentate da spazi
- Vi sono dei simboli di controllo all’inizio e alla fine del simbolo, rappresentati dalla sequenza “101”, dove con “1” si intende una barra e “0” uno spazio, e uno al centro, rappresentato dal simbolo “01010”
- Il simbolo di controllo centrale divide il simbolo in 2 parti, la metà sinistra e la metà destra, ciascuna delle quali codifica un numero di 6 cifre
Nella codifica originale, delle sei cifre della metà sinistra, la prima è riservata a determinare la destinazione d’uso del codice (per esempio l’1 è destinato all’uso generico di commercio mentre il 2 è destinato all’uso interno del magazzino) e le restanti 5 cifre identificano il produttore del bene codificato, secondo la numerazione assegnata dal consorzio.
Delle 6 cifre della metà destra, le prime 5 sono destinate a identificare il singolo prodotto, limitatamente al produttore specificarto e l’ultima cifra è un Check Digit, calcolato a partire dal resto del codice e viene utilizzato per individuare eventuali errori di lettura.
Osservando il simbolo del codice, notiamo subito che vi è un assembramento di barre (e spazi) di differenti spessori. In realtà ogni barra ha uno spessore che è multiplo di uno spessore fondamentale detto modulo.
Secondo lo standard, lo spessore nominale del modulo elementare è di 0.33mm e la sua altezza raccomandata è di 25.9mm, ma un simbolo può essere scalato in diverse proporzioni per adattarsi alle necessità.
Ciò che rende possibile al lettore di riconoscere il codice indipendentemente dalle sue dimensioni è la proporzionalità.
Il raggio laser del lettore infatti attraversa le linee del barcode secondo una retta (nell’immagine sotto ipotizziamo due direzioni di lettura r e r’), mentre le barre del codice rappresentano un fascio di parallele (nell’immagine sotto possiamo pensare che a, b e c siano i bordi delle barre del codice). Siamo quindi nelle condizioni del teorema di Talete che garantisce che indipendentemente dalla direzione di lettura, la proporzione fra gli spessori delle barre sarà sempre la stessa (cioè AB:BC=A’B’:B’C’).
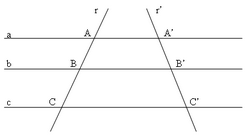
Allo scanner sarà quindi sufficiente misurare gli spessori del carattere di controllo “101” presente all’inizio e alla fine del simbolo per capire quanto è largo ciascun “modulo” e prenderlo come unità di misura di tutto il codice.
Inoltre la presenza del carattere di controllo sia all’inizio che alla fine fa capire allo scanner che il barcode è stato effettivamente scansionato per intero.
La codifica di ciascuna cifra all’interno del simbolo sfrutta 7 moduli, il che, sommando anche i caratteri di controllo porta a 95 il numero totale di moduli utilizzati per ciascun codice completo.
Nella tabella seguente è visibile la codifica di ciascuna cifra, indicando con “1” una barra dello spessore di un modulo e con “0” uno spazio dello spessore di un modulo.
1 2 3 4 5 6 7 8 9 |
0011001 0010011 0111101 0100011 0110001 0101111 0111011 0110111 0001011 |
1100110 1101100 1000010 1011100 1001110 1010000 1000100 1001000 1110100 |
La codifica “O” (dove la O sta per Odd Parity e si riferisce al fatto che le barre in ogni cifra sono sempre in numero dispari) è utilizzata per codificare la metà sinistra del codice mentre la codifica “E” (che sta per Even Parity e indica che le barre sono sempre in numero pari) è utilizzata per codificare la metà destra del simbolo.
Notiamo che tutti i caratteri della codifica O iniziano con uno spazio e finiscono con una Barra e viceversa per la codifica E. Questo significa che in due caratteri adiacenti, compresi i caratteri di controllo, l’ultimo modulo a destra del carattere di sinistra è sempre diverso dal primo modulo a sinistra del carattere di destra. Questo è indispensabile per il riconoscimento dei singoli caratteri.
Inoltre l’asimmetria di codifica fra le due metà, destra e sinistra, è indispensabile per far capire al lettore l’orientamento del codice rispetto alla direzione di scansione.
Quello descritto finora è il meccanismo di codifica relativo allo standard UPC americano, creato nel 1973. Pochi anni dopo, nel 1977, anche in Europa fu evidente la necessità di dotarsi di un analogo tipo di codice.
Rispetto allo standard americano, quello europeo, che fu chiamato EAN, aveva la necessità di discriminare, oltre il prodotto e il produttore, anche il paese di provenienza.
Per questo motivo il nuovo standard fu fatto derivare dall’UPC con l’aggiunta di una cifra a sinistra. Per questo motivo viene spesso denominato EAN-13, anche per distinguerlo da una versione ridotta dello stesso denominata EAN-8.
Le prime due cifre a sinistra del nuovo codice (e in qualche caso le prime 3) servono ad identificare il paese di origine, o più precisamente, l’autorità che si occupa di assegnare i codici per quel paese, o gruppo di paesi.
Il codice è pensato per essere retrocompatibile con lo standard UPC, infatti se la cifra aggiunta a sinistra è uno 0, il resto del codice coincide perfettamente con un codice di tipo UPC. Quindi un lettore in grado di leggere un codice EAN è sicuramente in grado di leggere anche un codice UPC.
L’elenco dei codici riservati ai vari paesi è riportato in questo e possiamo vedere che i prodotti codificati dall’autorità italiana hanno un codice che inizia per 80 o 81 (anche se il paese dove viene effettivamente prodotto l’articolo può essere qualunque).
La codifica di un codice EAN è leggermente più complessa dell’UPC.
Come abbiamo detto si tratta di un codice a 13 cifre. Di queste 13 la prima in realtà non è rappresentata nel codice a barre, ma il lettore la determina attraverso l’analisi della codifica della metà sinistra del codice.
Mentre per il codice UPC avevamo solo due codifiche, la “O” e la “E”, nel codice EAN ce ne sono 3, denominate “A”, “B” e “C”.
| Cifra | Codifica metà sinistra | Codifica metà destra | |
| Parità dispari (Codifica A) | Parità pari (Codifica B) | Parità dispari (Codifica C) | |
| 0 | 0001101 | 0100111 | 1110010 |
| 1 | 0011001 | 0110011 | 1100110 |
| 2 | 0010011 | 0011011 | 1101100 |
| 3 | 0111101 | 0100001 | 1000010 |
| 4 | 0100011 | 0011101 | 1011100 |
| 5 | 0110001 | 0111001 | 1001110 |
| 6 | 0101111 | 0000101 | 1010000 |
| 7 | 0111011 | 0010001 | 1000100 |
| 8 | 0110111 | 0001001 | 1001000 |
| 9 | 0001011 | 0010111 | 1110100 |
Quindi nel codice EAN, mentre la metà destra del simbolo è codificata sempre in parità dispari, esattamente come nell’UPC, nella metà sinistra ogni cifra ha una codifica che può essere sia pari che dispari (cioè essere codifica o secondo A o secondo B).
Ciò che decide la sequenza di codifica della metà sinistra è proprio la prima cifra aggiuntiva, quella che non viene rappresentata, secondo il seguente schema.
| Prima cifra | Parità da utilizzare | |||||
| Seconda cifra | Codice produttore | |||||
| 1 | 2 | 3 | 4 | 5 | ||
| 0 (UPC-A) | Dispari | Dispari | Dispari | Dispari | Dispari | Dispari |
| 1 | Dispari | Dispari | Pari | Dispari | Pari | Pari |
| 2 | Dispari | Dispari | Pari | Pari | Dispari | Pari |
| 3 | Dispari | Dispari | Pari | Pari | Pari | Dispari |
| 4 | Dispari | Pari | Dispari | Dispari | Pari | Pari |
| 5 | Dispari | Pari | Pari | Dispari | Dispari | Pari |
| 6 | Dispari | Pari | Pari | Pari | Dispari | Dispari |
| 7 | Dispari | Pari | Dispari | Pari | Dispari | Pari |
| 8 | Dispari | Pari | Dispari | Pari | Pari | Dispari |
| 9 | Dispari | Pari | Pari | Dispari | Pari | Dispari |
In questo caso possiamo osservare che:
- Se la prima cifra è 0, come anticipato, tutte le cifre della metà sinistra sono codificate con parità dispari. In questo modo il codice diventa a tutti gli effetti un UPC-A
- Se la prima cifra è diversa da 0, le 5 cifre del codice produttore hanno sempre due cifre codificate dispari e 3 cifre codificate pari.
- La prima cifra del codice UPC era riservata per la destinazione d’uso del codice, mentre nel codice EAN le prime due cifre identificano il paese e il sistema di codifica. Quindi in entrambi i casi le cifre destinate al codice produttore sono 5
- Il valore della prima cifra del codice viene quindi determinato riconoscendo lo schema di parità che è stato utilizzato nelle 6 cifre della metà di sinistra
Ultimo aspetto da esaminare nella codifica di un codice a barre è l’ultima cifra, detta check digit.
Essa rappresenta un valore di controllo che viene determinato dal valore delle restanti cifre e permette quindi di controllare se tutte le cifre sono state lette correttamente.
Il suo valore si calcola come segue, supponendo di avere un codice completo di check digit, cioè con tutte e 13 le cifre, e di voler verificare se il suo valore sia corretto.
- Il codice va considerato leggendolo da destra verso sinistra. Partendo dalla posizione 2 sommare i valori dei caratteri in posizione pari.
- Moltiplicare per 3 il risultato dell’operazione 1.
- Partendo dalla posizione 3 sommare i valori dei caratteri in posizione dispari.
- Sommare i risultati delle operazioni 2 e 3.
- Il check digit è il più piccolo numero che sommato al risultato dell’operazione 4 da un numero multiplo di 10. In termini matematici, sia X il valore appena determinato, la cifra di controllo vale: Y = 10 – (X mod 10)
La codifica di cui abbiam parlato finora riguarda i cosiddetti prodotti a quantità fissa, in cui è sufficiente indicare il produttore e un numero identificativo del prodotto per individuarlo in maniera univoca.
Il sistema GS1 però prevede una codifica anche per i prodotti cosiddetti “a peso variabile“. Questo fornisce un mezzo per catalogare anche quei prodotti che vengono venduti sfusi o confezionati sul momento dal venditore, come pane, salumi, latticini, ortofrutta. Prodotti che vengono generalmente individuati col termine di “freschi“.
 La codifica di questo genere di prodotti è lasciata alla gestione degli organismi nazionali, quindi in Italia lo standard per i prodotti freschi è stato emesso direttamente dall’Indicod-Ecr. A sinistra ne vediamo un esempio, tratto direttamente dal sito dell’Indicod.
La codifica di questo genere di prodotti è lasciata alla gestione degli organismi nazionali, quindi in Italia lo standard per i prodotti freschi è stato emesso direttamente dall’Indicod-Ecr. A sinistra ne vediamo un esempio, tratto direttamente dal sito dell’Indicod.
In questo caso è stato utilizzato un EAN-13 in cui le cifre a sinistra sono 2 e 9 e fanno sì che il codice ricada nel gruppo riservato alla gestione interna al venditore.
A parte la cifra di controllo, le ultime cifre rappresentano direttamente il prezzo, calcolato al momento della pesatura.
Codici EAN per le prime cifre identificative del paese
| 00-13: USA & Canada | 20-29: In-Store Functions | 30-37: France |
| 40-44: Germany | 45: Japan (also 49) | 46: Russian Federation |
| 471: Taiwan | 474: Estonia | 475: Latvia |
| 477: Lithuania | 479: Sri Lanka | 480: Philippines |
| 482: Ukraine | 484: Moldova | 485: Armenia |
| 486: Georgia | 487: Kazakhstan | 489: Hong Kong |
| 49: Japan (JAN-13) | 50: United Kingdom | 520: Greece |
| 528: Lebanon | 529: Cyprus | 531: Macedonia |
| 535: Malta | 539: Ireland | 54: Belgium & Luxembourg |
| 560: Portugal | 569: Iceland | 57: Denmark |
| 590: Poland | 594: Romania | 599: Hungary |
| 600 & 601: South Africa | 609: Mauritius | 611: Morocco |
| 613: Algeria | 619: Tunisia | 622: Egypt |
| 625: Jordan | 626: Iran | 64: Finland |
| 690-692: China | 70: Norway | 729: Israel |
| 73: Sweden | 740: Guatemala | 741: El Salvador |
| 742: Honduras | 743: Nicaragua | 744: Costa Rica |
| 746: Dominican Republic | 750: Mexico | 759: Venezuela |
| 76: Switzerland | 770: Colombia | 773: Uruguay |
| 775: Peru | 777: Bolivia | 779: Argentina |
| 780: Chile | 784: Paraguay | 785: Peru |
| 786: Ecuador | 789: Brazil | 80 - 83: Italy |
| 84: Spain | 850: Cuba | 858: Slovakia |
| 859: Czech Republic | 860: Yugloslavia | 869: Turkey |
| 87: Netherlands | 880: South Korea | 885: Thailand |
| 888: Singapore | 890: India | 893: Vietnam |
| 899: Indonesia | 90 & 91: Austria | 93: Australia |
| 94: New Zealand | 955: Malaysia | 977: International Standard Serial Number for Periodicals (ISSN) |
| 978: International Standard Book Numbering (ISBN) | 979: International Standard Music Number (ISMN) | 980: Refund receipts |
| 981 & 982: Common Currency Coupons | 99: Coupons | |
 -0
-0  )
)

Lascia un commento