Reti neurali in azione

I fotogrammi sopra appartengono ad una famosa sequenza tratta dal film Blade Runner, diretto da Ridley Scott nel 1982, dove il protagonista, Rick Deckard interpretato da Harrison Ford, chiede ad un computer di analizzare un immagine estraendone un particolare.
Nell’immagine originale il particolare è estremamente piccolo e quasi indistinguibile, ma la macchina è in grado di ingrandirlo svariate volte e compensare la naturale sgranatura dell’immagine che consegue l’ingrandimento.
Fino a poco tempo fa, per accettare questa capacità della macchina, era necessaria una certa sospensione di incredulità e ammettere che, in un futuro in cui si prevede che ci siano androidi virtualmente indistinguibili da esseri umani, un semplice computer sia perfettamente in grado di ingrandire una fotografia all’infinito senza perdere di definizione.
Ovviamente, utilizzare procedimenti matematici che estrapolino un’immagine a risoluzione maggiore a partire da una meno definita è impossibile, a meno di non accettare una certa perdita di nitidezza rispetto all’originale. Perché l’algoritmo dovrebbe creare dei dettagli che nei suoi dati di input, semplicemente, non sono presenti.
L’intelligenza artificiale ha ormai ribaltato questa limitazione. Esattamente come un essere umano è in grado di riconoscere il soggetto di una fotografia estremamente danneggiata o pesantemente sfocata, o identificare un personaggio famoso ritratto in forma caricaturale, attingendo alle informazioni già immagazzinate nel proprio cervello e usandole come strumento interpretativo, così i nuovi analizzatori di immagini basati di intelligenza artificiale sono in grado di ricostruire l’informazione mancante durante il processo di ingrandimento attingendo alla “esperienza” maturata nell’analisi delle miliardi di immagini utilizzate nella fase di training.
In un certo senso, l’intelligenza artificiale “sa” come dovrebbe apparire un certo soggetto se fosse ripreso a risoluzione maggiore e ci restituisce questo risultato quando le presentiamo la versione bassa risoluzione.
A causa della crescente diffusione di queste tecnologie, ci sono dei termini, spesso mutuati dall’inglese, che si possono incontrare anche in contesti non specialistici: Machine Learning, per riferirsi all’insieme di algoritmi di apprendimento supervisionato e non di cui abbiamo parlato, Artificial Neural Network, per individuare una rete neurale semplice come quella illustrata nel paragrafo precedente, Deep Neural Network, per indicare una rete con molti strati nascosti e algoritmi più sofisticati nella definizione dei suoi neuroni e la propagazione dei dati al suo interno.
Ciò che ha reso possibile i risultati di elaborazione grafica come quelli descritti sopra sono le cosiddette reti neurali convoluzionali che appartengono di buon diritto alla categoria delle Deep Neural Network. Una CNN (Convolutional Neural Network) è un particolare tipo di rete feedforward in cui lo strato di neuroni di input viene alimentato con dati provenienti da una immagine. Lo strato di input agisce come una sorta di lente che scorre lungo l’immagine e alimenta gli strati nascosti che ne estraggono le caratteristiche grafiche.

Gli strati più profondi della rete agiscono da classificatori per le caratteristiche riconosciute.
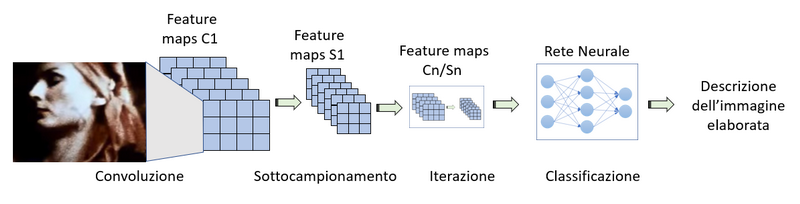
Una rete di questo tipo può imparare a riconoscere gli oggetti e le persone rappresentati nelle immagini ed è così che il nostro smartphone può riconoscere i nostri amici e parenti quando li fotografiamo basandosi sulle foto del loro profilo presenti nei nostri contatti.
L’evoluzione delle CNN prende il nome di rete GAN (Generative Adversarial Network – Rete Generativa Avversaria) in cui due reti CNN sono collegate in modo che una produca un’immagine basandosi su una descrizione testuale e l’altra verifichi che l’immagine prodotta sia effettivamente riconoscibile.
Un’applicazione dimostrativa di questa tecnica è realizzata dal progetto Dall-E2 di Open AI in grado di generare opere d’arte con risoluzione fotorealistica basandosi su delle descrizioni date dall’utente. Un’applicazione più pratica è quella di dotare i veicoli a guida autonoma una certa capacità di visione artificiale per riconoscere gli ostacoli durante la guida.
Questa capacità di riconoscimento e sintesi si può applicare facilmente anche al campo audio.
Fino a poco tempo fa, basandosi puramente su metodi analitici, era possibile estrapolare le singole parti di una canzone partendo dal pezzo finito.
Elaborando il segnale, basandosi sulle frequenze tipiche di ciascuno strumento, si riusciva in maniera anche piuttosto soddisfacente ad estrarre la parte cantata, o la traccia di chitarra solista, ma rimaneva sempre una piccola percentuale in sottofondo del mix completo della canzone.
Oggi i nuovi plugin di elaborazione audio possono utilizzare l’intelligenza artificiale per capire cosa stia suonando uno strumento e ricostruirlo in maniera indipendente dal sottofondo.
Purtroppo a fianco delle enormi e utili applicazioni pratiche di questa tecnologia si aprono scenari inquietanti in cui l’applicazione della generazione di immagini e suoni prende il nome di Deep Fake.
Ora che il computer è in grado di generare immagini foto realistiche a comando è infatti possibile creare filmati in cui si possono creare animazioni in cui un personaggio famoso, un politico o un attore, fa e dice cose determinate dall’intelligenza artificiale. Tali applicazioni diventano sempre più accurate e non è difficile immaginare un futuro in cui la distinzione da una ripresa reale da una artificiale diventi estremamente arduo.
 -0
-0  )
)

Lascia un commento