La matematica della mente
Complice l’aumento della potenza di calcolo dei computer, i decenni successivi hanno visto nascere diversi modelli di neuroni, tipi di reti e algoritmi di apprendimento tali che oggi le reti neurali sono un campo di studio vastissimo con applicazioni le più disparate.
In questo capitolo un po’ più tecnico descriviamo il funzionamento di un tipo di rete, discendente diretta del percettrone visto precedentemente, il cui modello di funzionamento è alla basa di implementazioni più moderne: le reti feed-forward multistrato (reti multistrato a flusso in avanti).
Prima di addentrarci nella descrizione delle reti, però, è il caso di descrivere il modello di neurone artificiale come viene generalmente inteso nella sua accezione più moderna.
Nell’immagine sotto ne vediamo una rappresentazione grafica.
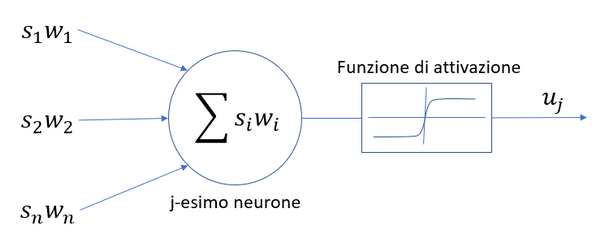
Il neurone artificiale preso singolarmente è un oggetto matematico a cui afferiscono gli impulsi provenienti dall’esterno o da altri neuroni e che nell’immagine sono indicati con si. A ciascun impulso è associato un peso wi che determina quanto quel particolare impulso abbia effetto sulla risposta del neurone.
Dato l’insieme degli impulsi pesati, il neurone ne effettua la somma, che è come dire che gli impulsi raggiungono tutti insieme il monticolo assonico, e al valore di questa sommatoria si applica una cosiddetta funzione di attivazione, che serve a simulare la scarica del potenziale d’azione lungo l’assone.
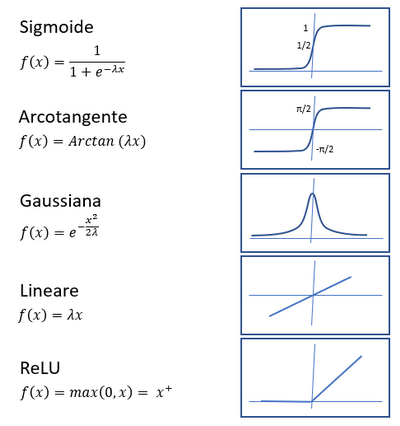
Proprio ad imitazione del comportamento tutto-o-niente della scarica neuronale, le prime funzioni di attivazione ad essere state usate (dopo la funzione a gradino discreto di Rosenblatt) sono state la funzione sigmoide o l’arcotangente che presentano, come si può vedere nell’immagine, un andamento a gradino continuo, eventualmente con un paramento λ per regolarne la ripidezza. In tempi più recenti si è affermata la funzione ReLU (Rectified Linear Unit) o rettificatore, che si rivela più efficiente in fase di apprendimento.
Le reti di tipo feed-forward sono le dirette discendenti del percettrone. I neuroni sono organizzati in strati e quelli appartenenti ad uno strato non hanno connessioni fra di loro ma solo con lo stato successivo nella direzione di propagazione.
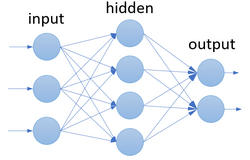 Esse sono caratterizzate da una propagazione in avanti del dato, che viene presentato inizialmente allo strato di neuroni di input in cui ciascun neurone effettua la media pesata dei valori in ingresso con conseguente funzione di attivazione. come illustrato sopra. Dopo lo strato di input è presente almeno uno strato “nascosto” (hidden) i cui neuroni prelevano l’uscita dello strato precedente e lo processano in maniera del tutto simile. Il processo si ripete finché il dato viene prelevato come uscita finale dallo strato di output.
Esse sono caratterizzate da una propagazione in avanti del dato, che viene presentato inizialmente allo strato di neuroni di input in cui ciascun neurone effettua la media pesata dei valori in ingresso con conseguente funzione di attivazione. come illustrato sopra. Dopo lo strato di input è presente almeno uno strato “nascosto” (hidden) i cui neuroni prelevano l’uscita dello strato precedente e lo processano in maniera del tutto simile. Il processo si ripete finché il dato viene prelevato come uscita finale dallo strato di output.
L’apprendimento della rete è di tipo supervisionato, cioè si realizza presentando in ingresso alla rete una serie di dati, detto training set, per i quali si conosce già il risultato esatto che la rete dovrebbe calcolare in uscita.
All’inizio del processo, l’uscita della rete differirà da quella attesa per cui si potrà calcolare un errore (per esempio come somma dei quadrati degli scarti) da utilizzare per effettuare le opportune correzioni.
Il metodo più usato per correggere i valori dei pesi è detto di backpropagation, cioè di retro-propagazione dell’errore.
Tale metodo prevede prelevare il dato in uscita e di calcolare l’errore rispetto il risultato atteso per tutto il set di training. Dall’errore si può quindi calcolare di quanto modificare i singoli pesi in ingresso per minimizzarlo realizzando la cosiddetta discesa del gradiente. Infine, la retro-propagazione consiste nel ripetere questo procedimento “all’indietro” cioè utilizzare l’errore “pesato” con i pesi dello strato successivo per utilizzarlo come errore dello strato precedente e ripetere il procedimento per risalire fino allo strato di input.
Dopo un certo numero di iterazioni del processo di backpropagation i valori dei pesi, se i parametri sono stati scelti correttamente, convergono su dei valori che garantiscono che l’output della rete sia il più vicino possibile ai dati di training.
Una rete così addestrata è in grado di calcolare in maniera molto efficiente un output anche quando le si presenta un dati in ingresso che non erano presenti nel set di training effettuando di fatto una estrapolazione basandosi su pattern intrinseci ai dati già noti, senza che i programmatori abbiano inserito nessun algoritmo esplicitamente pensato per interpretare quei dati specifici. Esistono anche varianti (reti di Elman o reti di Jordan) in cui il valore in uscita viene riportato come dato in ingresso generando una ricorsività che ha l’effetto di introdurre la dimensione temporale nel funzionamento della rete.
E’ importante sottolineare come questo tipo di reti lavorino con funzioni continue in modo sincrono. In altre parole il dato viene presentato allo strato di input, se ne calcola l’uscita ottenendo un valore per ogni neurone e si ripete il processo per tutti i neuroni negli strati successivi fino a ricavare un valore per l’output. Lo sforzo computazionale quindi è considerevole, non solo in fase di calcolo, ma soprattutto durante la fase di training. Tanto che oggi i colossi del web come Google o Amazon offrono un servizio di training per reti neurali in cui gli utenti possono utilizzare i loro potenti centri di calcolo per effettuare questa operazione e ricevere in uscita la rete addestrata per essere utilizzata nell’applicazione finale.
 -0
-0  )
)

Lascia un commento